
リソース設計の実践 — AIに伝わるデータ構造の考え方
バイブコーディング入門 — 第13回
前回のおさらいと、今回のテーマ
前回(第12回)では、REST APIの設計パターンを学んだ。URLでリソース(操作対象)を示し、HTTPメソッド(GET・POST・PUT・DELETE)で操作を表すという規則だった。
今回は、その手前にある「そもそもリソースをどう設計するか」という話だ。
バイブコーディングでAIにアプリを作ってもらうとき、「タスク管理アプリを作って」とだけ伝えると、AIはそれなりのものを作ってくれる。しかし、業務が複雑になるほど「それなり」では足りなくなる。「案件ごとにタスクを分けたい」「担当者ごとの進捗を見たい」「月別の集計が欲しい」——こうした要望を的確に伝えるには、データの構造を自分で整理できる力が必要だ。
リソース設計というと難しく聞こえるが、やっていることは「業務で使う情報を、種類ごとに整理して名前を付ける」ことだ。引き出しにラベルを貼るのと同じ作業だと思ってほしい。
この記事では、架空の業務管理アプリを題材に、リソース設計を一緒にやってみる。読み終わったあと、あなたが自分の業務アプリのデータ構造をAIに的確に伝えられるようになることがゴールだ。
リソース設計とは何か — 引き出しにラベルを貼る作業
リソース設計を一言でまとめると、「アプリで扱うデータの種類を決め、それぞれの関係を整理すること」だ。
たとえば、あなたが10人規模の制作会社を経営しているとする。日々の業務で扱う情報を書き出すと、こんなリストになる。
- 案件の情報(クライアント名、納期、予算)
- タスクの情報(作業内容、担当者、期限、進捗)
- スタッフの情報(名前、役職、スキル)
- クライアントの情報(会社名、担当者名、連絡先)
- 請求書の情報(金額、発行日、支払期限、入金状況)
これらの情報の「種類」が、それぞれ1つのリソースになる。REST APIの言葉で言えば、/api/projects、/api/tasks、/api/staff、/api/clients、/api/invoices というエンドポイント(APIの住所)が対応する。
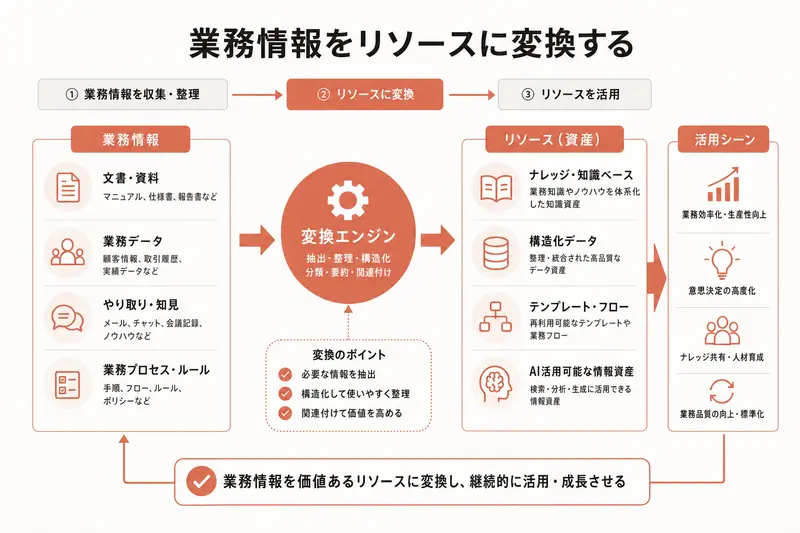
この「情報の種類を洗い出して、名前を付ける」のがリソース設計の第一歩だ。
ステップ1: 業務フローからリソースを洗い出す
リソース設計の最初のステップは、「自分の業務で、どんな情報をやりとりしているか」を書き出すことだ。
いきなりAPIの設計を考える必要はない。普段の業務フローを思い浮かべて、そこに登場する「名詞」を拾っていけばよい。
制作会社の業務フローを例にやってみよう。
フロー1: 新規案件の受注 → クライアントから問い合わせが来る → 見積もりを出す → 受注が決まる → 案件として登録する
登場する名詞: クライアント、見積もり、案件
フロー2: 制作の進行 → 案件をタスクに分解する → 担当者を割り当てる → 進捗を確認する → 納品する
登場する名詞: 案件、タスク、担当者(スタッフ)、納品物
フロー3: 請求・入金 → 納品後に請求書を発行する → 入金を確認する → 完了処理をする
登場する名詞: 請求書、入金記録
これを整理すると、このアプリに必要なリソースが見えてくる。
- clients(クライアント)
- estimates(見積もり)
- projects(案件)
- tasks(タスク)
- staff(スタッフ)
- deliverables(納品物)
- invoices(請求書)
- payments(入金記録)
8つのリソースが出てきた。ここで大切なのは、最初から完璧を目指さないことだ。まずは思いつくものを全部書き出して、あとから整理すればよい。AIに伝えるときも、「まずこのリソースで作ってみて、足りなければ追加する」というやり方で構わない。
ステップ2: 各リソースの「中身」を決める
リソースの種類が決まったら、次はそれぞれの中身(フィールド、項目)を考える。
Excelの表を思い浮かべてほしい。1つのリソースが1つの表で、列の見出しがフィールドだ。
projects(案件)の表:
| フィールド名 | 日本語 | 例 |
|---|---|---|
| id | 案件番号 | 1, 2, 3... |
| name | 案件名 | Webサイトリニューアル |
| client_id | クライアント番号 | 42 |
| status | ステータス | 進行中 / 完了 / 保留 |
| budget | 予算(税抜) | 500000 |
| deadline | 納期 | 2026-05-31 |
| created_at | 登録日 | 2026-04-01 |
tasks(タスク)の表:
| フィールド名 | 日本語 | 例 |
|---|---|---|
| id | タスク番号 | 1, 2, 3... |
| project_id | 案件番号 | 1 |
| title | タスク名 | ワイヤーフレーム作成 |
| assignee_id | 担当者番号 | 5 |
| status | ステータス | 未着手 / 進行中 / 完了 |
| due_date | 期限 | 2026-04-20 |
| priority | 優先度 | high / medium / low |
ここで注目してほしいのが client_id や project_id、assignee_id という項目だ。これが「他のリソースとの繋がり」を表している。tasks の project_id に「1」が入っていれば、「案件番号1に属するタスク」という意味になる。
フィールドを決めるときのコツは3つある。
1つ目: 業務で実際に使っている情報だけを入れる。「あったら便利かも」は入れない。あとから追加するほうがずっと楽だ。
2つ目: ステータスの選択肢は最初に決めておく。「進行中」「作業中」「対応中」が混在すると混乱する。3〜5個に絞るのが一般的だ。
3つ目: 金額や日付のフォーマットを統一する。金額は税抜きの整数(500000)、日付はYYYY-MM-DD形式(2026-04-20)が扱いやすい。
ステップ3: リソース同士の関係を整理する
リソース設計で最も重要なのが、リソース同士の「つながり」を整理することだ。データベースの世界では「リレーション(関連)」と呼ぶが、ここでは「親子関係」と「参照関係」の2種類だけ覚えておけば十分だ。
親子関係: 「1つの親に、複数の子がぶら下がる」パターン
1つのクライアントが、複数の案件を持つ → clients(親)→ projects(子)
1つの案件が、複数のタスクを持つ → projects(親)→ tasks(子)
1つの案件が、複数の請求書を持つ → projects(親)→ invoices(子)
参照関係: 「このデータは、あのデータと繋がっている」パターン
タスクには担当者(staff)が割り当てられる → tasks → staff(assignee_id で参照)
請求書にはクライアントが紐づく → invoices → clients(client_id で参照)
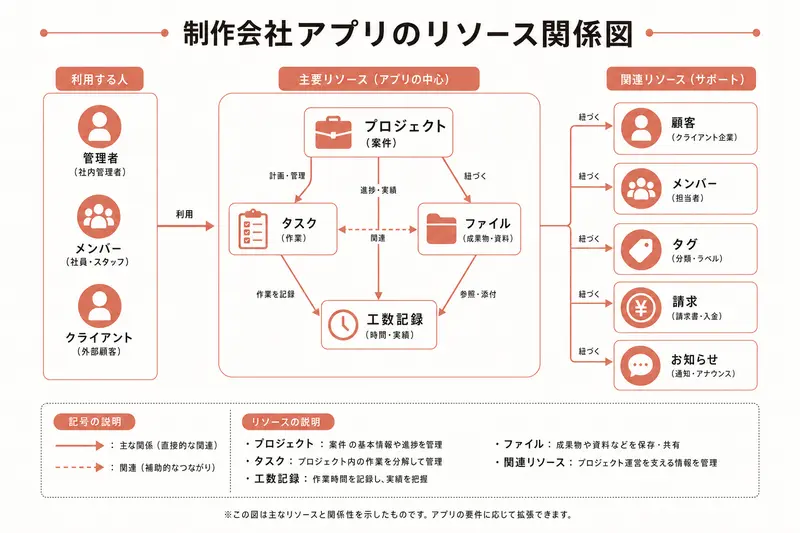
この関係が分かっていると、REST APIのURLも自然に決まる。
- クライアント42番の案件一覧 → GET /api/clients/42/projects
- 案件1番のタスク一覧 → GET /api/projects/1/tasks
- 案件1番の請求書一覧 → GET /api/projects/1/invoices
前回学んだネスト(入れ子)URLだ。親子関係がそのままURLの構造に反映される。
ステップ4: AIに伝えるための整理術
リソースの洗い出し、フィールドの設計、関係の整理ができたら、いよいよAIに伝える段階だ。ここが一番大事なところだ。
「業務管理アプリを作って」という曖昧な依頼と、リソース設計を整理した上での依頼では、AIの出力品質がまるで違う。
具体的な伝え方のテンプレートを紹介する。
AIへの依頼テンプレート:
「制作会社の業務管理アプリを作りたい。
リソースは以下の通り:
- clients(クライアント): name, email, phone, company
- projects(案件): name, client_id, status(pending/active/completed/on_hold), budget, deadline
- tasks(タスク): title, project_id, assignee_id, status(todo/in_progress/done), due_date, priority(high/medium/low)
- staff(スタッフ): name, role, email
- invoices(請求書): project_id, client_id, amount, issued_date, due_date, status(draft/sent/paid)
関係:
- 1つの client が複数の projects を持つ
- 1つの project が複数の tasks と invoices を持つ
- task の assignee_id は staff を参照
最初に projects の一覧画面と、project 詳細画面(タスク一覧付き)を作ってほしい。」
このテンプレートのポイントは4つある。
1つ目: リソース名を英語で明示する。AIはこの名前をそのままAPIのURLやデータベースのテーブル名に使う。
2つ目: フィールド名も英語で列挙する。日本語で「案件名」と書くよりも、name と書いたほうがAIは迷わない。
3つ目: ステータスの選択肢をカッコ内に書く。AIが勝手に選択肢を作ると、業務に合わないものになることがある。
4つ目: リソース間の関係を箇条書きで明示する。「client が複数の projects を持つ」と書けば、AIは client_id をprojects テーブルに自動で追加してくれる。
実践: 3つの業種でリソース設計をやってみる
ここからは、読者のみなさんが自分の業務に当てはめやすいように、3つの業種でリソース設計の例を紹介する。
例1: 士業事務所(税理士・社労士)の案件管理
業務フロー: 顧問先から依頼 → 案件として受付 → 担当者が作業 → 納品(申告書・届出等)→ 請求
リソース:
- clients(顧問先): company_name, representative, email, phone, contract_type
- cases(案件): client_id, title, category(tax_return/payroll/consultation/other), status, deadline, assignee_id
- documents(書類): case_id, name, file_url, doc_type, submitted_at
- staff(スタッフ): name, role, specialization
- billings(請求): case_id, client_id, amount, billing_date, status
関係: 1つの顧問先 → 複数の案件 → 各案件に複数の書類。案件ごとに担当者を割り当て。
例2: 小規模ECショップの受注管理
業務フロー: 商品を登録 → 注文が入る → 在庫を確認 → 発送 → 入金確認
リソース:
- products(商品): name, price, stock_count, category, image_url
- orders(注文): customer_name, customer_email, total_amount, status(pending/confirmed/shipped/delivered), ordered_at
- order_items(注文明細): order_id, product_id, quantity, unit_price
- shipments(発送): order_id, tracking_number, carrier, shipped_at, delivered_at
関係: 1つの注文 → 複数の注文明細(商品ごとに1行)。1つの注文 → 1つの発送記録。
例3: マーケティング会社のキャンペーン管理
業務フロー: クライアントからの依頼 → キャンペーン企画 → コンテンツ制作 → 配信 → レポート
リソース:
- clients(クライアント): company_name, contact_name, email, industry
- campaigns(キャンペーン): client_id, name, platform(sns/email/web/print), budget, start_date, end_date, status
- contents(コンテンツ): campaign_id, title, content_type(image/video/text/landing_page), status(draft/review/approved/published), assignee_id
- reports(レポート): campaign_id, impressions, clicks, conversions, cost, period_start, period_end
- staff(スタッフ): name, role, skills
関係: 1つのクライアント → 複数のキャンペーン → 各キャンペーンに複数のコンテンツとレポート。
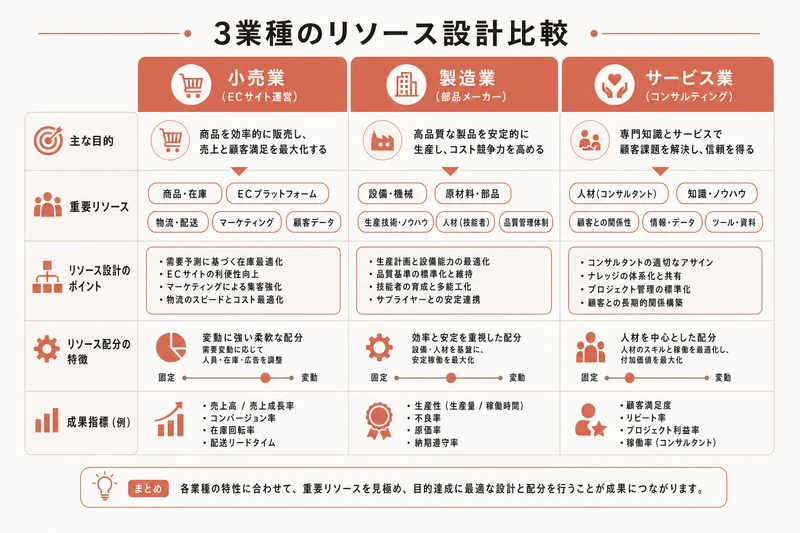
どの業種でも、基本的な構造は似ていることに気づくだろう。「顧客 → 案件 → 作業 → 成果物 → 請求」という流れが共通している。あなたの業務も、このパターンに当てはめて考えてみてほしい。
よくある設計ミスと対処法
ミス1: 1つのリソースに情報を詰め込みすぎる
よくある例: projects テーブルに、クライアント名、クライアントのメールアドレス、クライアントの電話番号を直接入れてしまう。
問題: クライアントの電話番号が変わったとき、そのクライアントに関連する全案件のデータを修正しないといけない。
対処: クライアント情報は clients リソースに分離し、projects には client_id だけを持たせる。これがリソースを分ける理由だ。
ミス2: ステータスの選択肢が多すぎる
よくある例: タスクのステータスを「未着手・準備中・着手前確認・進行中・レビュー待ち・レビュー中・修正中・最終確認・完了・保留・中止」の11段階にする。
問題: 「準備中」と「着手前確認」の違いが分からなくなり、誰も正しくステータスを更新しなくなる。
対処: まずは3〜5段階で始める。足りなければあとから追加する。「未着手・進行中・完了」の3つでも業務は十分回ることが多い。
ミス3: 最初から完璧を目指して手が止まる
よくある例: 「将来的にはこういう機能も必要になるかもしれない」と考えて、使うか分からないリソースまで設計してしまう。
問題: 設計フェーズに時間がかかりすぎて、いつまでもアプリが動かない。
対処: まずは核となる3〜4つのリソースだけで始める。バイブコーディングの利点は、あとからリソースを追加するのが比較的容易なことだ。AIに「このアプリに notifications(通知)リソースを追加して」と言えば、既存の構造に合わせて追加してくれる。
AIへのリソース設計依頼テンプレート集
ここまでの知識を活かせるテンプレートを3つ紹介する。コピーして、あなたの業務に合わせてカスタマイズしてほしい。
テンプレート1: ゼロからアプリを作るとき
「〇〇業の業務管理アプリを作りたい。
リソース:
- [リソース名]: [フィールド1], [フィールド2], [フィールド3]
- [リソース名]: [フィールド1], [フィールド2], [フィールド3]
- [リソース名]: [フィールド1], [フィールド2], [フィールド3]
関係:
- [リソースA] が複数の [リソースB] を持つ
- [リソースB] の [フィールド] は [リソースC] を参照
まず [リソース名] の一覧画面と登録フォームから作ってほしい。」
テンプレート2: 既存のアプリにリソースを追加するとき
「今のアプリに [リソース名]([日本語名])を追加したい。
フィールド: [フィールド1], [フィールド2], [フィールド3] ステータス: [選択肢1] / [選択肢2] / [選択肢3]
既存の [リソース名] との関係: 1つの [親リソース] に複数の [新リソース] がぶら下がる。
APIは REST の規則に従って、GET /api/[リソース名] で一覧取得、POST /api/[リソース名] で新規作成にしてほしい。」
テンプレート3: リソース設計自体をAIに相談するとき
「〇〇業で、日々の業務は [業務フローの説明] という流れ。
この業務をアプリ化したい。必要なリソース(データの種類)と、それぞれのフィールド(項目)、リソース間の関係を提案してほしい。
条件:
- リソースは最大5つまでに絞る
- ステータスの選択肢は各リソース3〜5個まで
- フィールド名は英語で
提案のあと、REST APIのエンドポイント一覧もまとめてほしい。」
テンプレート3のように、リソース設計そのものをAIに相談するのもよい方法だ。AIの提案を見て、「この項目は要らない」「ここにこのフィールドを足したい」と修正していけば、効率よく設計を固められる。
よくある不安と答え
リソース名の英語が分からないときはどうすればよいか
AIに「〇〇を英語でリソース名にするなら何が適切か」と聞けばよい。たとえば「顧問先」なら clients、「議事録」なら meeting_notes や minutes など、適切な名前を提案してくれる。リソース名は複数形(clients, projects, tasks)にするのが慣習だ。
フィールドはあとから追加・変更できるのか
できる。バイブコーディングでは、AIに「projects に description(案件の説明)フィールドを追加して」と言えば、データベースとAPIの両方を更新してくれる。ただし、既にデータが入っている状態でフィールドを削除すると、そのデータは消えてしまう。追加は気軽にできるが、削除は慎重にやるのが一般的だ。
リソースが多すぎるか少なすぎるか、どう判断すればよいか
目安として、最初のバージョンは3〜5つのリソースで始めるのが一般的だ。10を超えると管理が大変になる。「このリソースは本当に別で管理する必要があるか?」と自問して、答えが「ノー」なら、他のリソースのフィールドとして吸収できないか考えてみよう。
Excelで管理していたデータをそのままリソースにしてよいか
Excelのシートがそのままリソースになることが多い。ただし、1つのシートに複数の種類の情報が混在している場合は、リソースを分割したほうがよい。たとえば「案件管理シート」にクライアント情報とタスク情報が同居しているなら、clients、projects、tasks の3つに分けるとすっきりする。
まとめ
リソース設計は、「業務で使う情報を、種類ごとに整理して名前を付ける」作業だ。業務フローから名詞を拾い出し、各リソースのフィールドを決め、親子関係と参照関係を整理する。この3ステップを踏んでからAIに伝えると、あなたの業務にフィットしたアプリが出来上がる。最初から完璧を目指す必要はない。3〜5つのリソースで始めて、使いながら育てていくのがバイブコーディングのやり方だ。
次回は「APIのバージョニングとページネーション — 大量データを扱う設計テクニック」。アプリのデータが増えてきたとき、一覧画面の表示を速く保つためのページ送り(ページネーション)や、APIの仕様変更に備えるバージョニングの考え方を学ぶ。
参考リファレンス
- 前回: 第12回「REST APIの設計パターン — エンドポイントの規則性を知る」(/articles/vc-012)
- 次回: 第14回「APIのバージョニングとページネーション — 大量データを扱う設計テクニック」(/articles/vc-014)
- バイブコーディング入門 カリキュラム(/vibe-coding)