
競合リサーチを月3時間に減らす|ひとり事業主のための監視自動化
競合を毎日チェックするのは無理だ。でも月3時間なら続けられる。
ひとりで小さな事業を回していると、競合リサーチは必ず後回しになる。目の前の納品がある。問い合わせに返信しないといけない。経理も自分でやる。そんな中で、競合のサイトを毎日見に行って、価格ページの変更を追いかけて、SNSをスクロールして、ブログの新着を読むなんて、どう考えても続かない。
でも、やらないと怖い。気づいたら競合が新しいプランを出していて、自分の提案書が時代遅れになっている。そんな経験をした人は多いはずだ。
この記事では、競合リサーチを毎日の作業から月3時間の作業に圧縮する方法を書く。使うのは、Jina Reader API(ウェブページをAIが読みやすい形に変換してくれる外部サービス)と、簡単な自動化の仕組みだけだ。プログラマーでなくても、ほとんどの手順はそのまま真似できる。
この記事の前提
この記事は、ひとりか、せいぜい数人で事業を回している個人事業主に向けて書いている。マーケティング担当者が別にいる会社の話ではない。自分が営業で、自分が制作で、自分が経理で、時間がいくらあっても足りない人を想定している。
前提として、私はこう考えている。競合リサーチは、頻度ではなく精度で決まる。毎日見ても、ぼんやり眺めているだけなら意味がない。月に一度、深く読み込んで、自分の商品に反映できる気づきを2つか3つ拾えれば十分だ。
そして、深く読み込むための材料集めは、人間がやる仕事ではない。ここを自動化すれば、浮いた時間で本当にやるべき思考ができる。
競合リサーチが続かない本当の理由
多くの個人事業主は、競合リサーチをタスクとして捉えている。やることリストに「競合チェック」と書いて、週に一度、気合でサイトを巡回する。最初の2週間は続く。3週目から怪しくなる。1ヶ月後には消えている。
なぜ続かないか。理由は3つある。
1つ目は、情報を集めることと、情報を使うことが一緒になっているからだ。サイトを開いて、読んで、頭の中で整理して、自分の事業に当てはめて考える。これを同時にやろうとすると、脳の負担が大きすぎて、どこかで力尽きる。
2つ目は、監視対象が多すぎることだ。競合が10社あって、それぞれにサイト、ブログ、X、noteがあれば、チェック対象は40ヶ所になる。これを人力で追うのは不可能だ。
3つ目は、何も変わらない日が多いことだ。毎日見に行っても、95%の日は何も更新されていない。無駄足を踏み続けると、人間は必ずやめる。
この3つを解決する方法は、情報収集と思考を分離することだ。集めるのは機械に任せる。人間は、集まった差分だけを読む。月に一度、まとまった時間で。
全体像 情報を待つ仕組みを作る
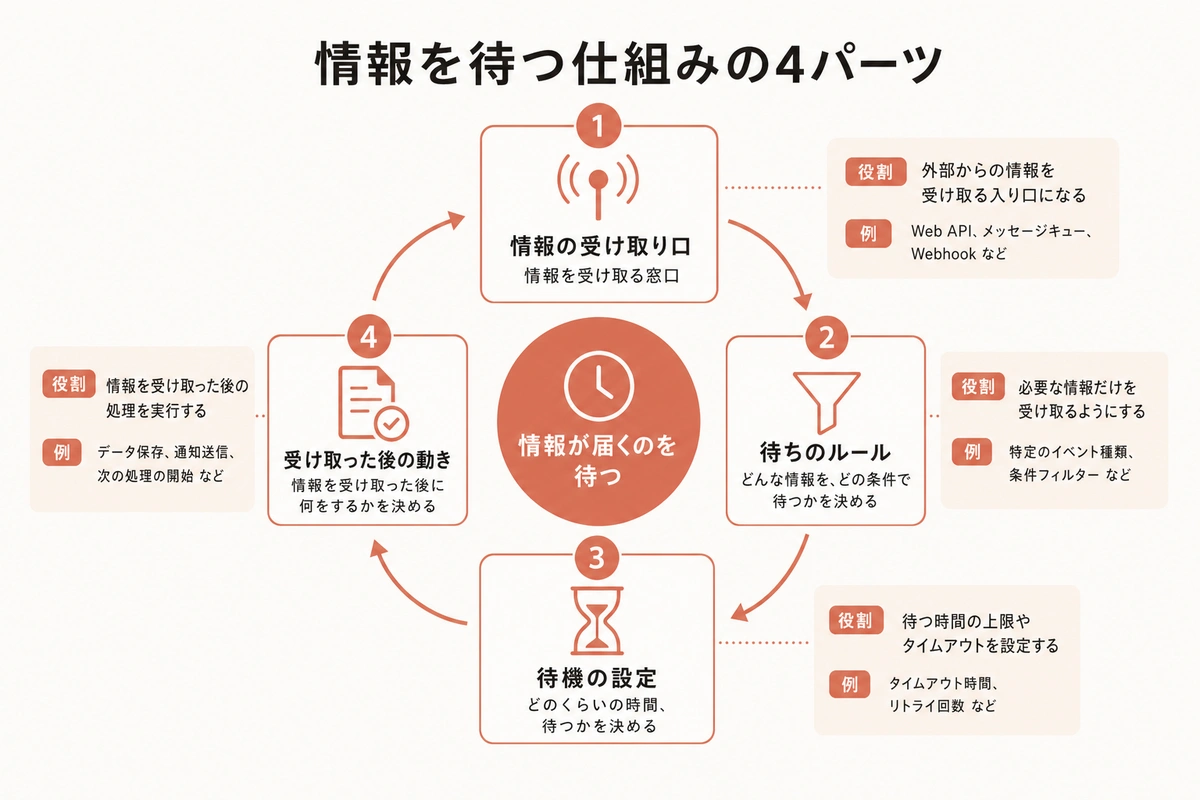
仕組みはシンプルだ。4つのパーツで構成する。
- 監視対象リスト 本当に見るべきURLを10個前後に絞る
- 定期取得 Jina Reader API でページの中身をテキストとして取得する
- 差分検知 前回と今回を比較して、変わった部分だけを抽出する
- 週次レポート 差分を1通のメールかドキュメントにまとめる
大事なのは、自分から見に行かないことだ。情報が向こうから届く状態を作る。そのために必要な技術は、思っているより少ない。
Jina Reader API を使う理由
Jina Reader は、ウェブページのURLを渡すと、広告やナビゲーションを取り除いた本文だけをテキストで返してくれるサービスだ。無料枠でもかなり使える。
なぜこれを使うのか。普通にウェブページをダウンロードすると、HTMLという人間が読みにくい形式で返ってくる。そこからヘッダー、フッター、サイドバー、広告を取り除いて、本文だけを抜き出す作業は、想像以上に面倒だ。Jina Reader はその面倒を全部やってくれる。
使い方は拍子抜けするほど簡単だ。調べたいURLの前に https://r.jina.ai/ をつけるだけでいい。
例えば、競合のA社の料金ページを見たいなら、こう書く。
https://r.jina.ai/https://claudelab.jp
これをブラウザで開いてみてほしい。料金ページの中身が、きれいなテキストで表示されるはずだ。ここからが本番だ。このテキストを定期的に取得して、前回と比較する。
監視対象の絞り込みが9割
自動化の話をする前に、どうしても伝えたいことがある。監視対象を絞り込むことが、この仕組み全体の成否を決める。
私は以前、ある個人事業主の相談を受けたとき、監視リストに30以上のURLが入っているのを見たことがある。大手競合、中堅競合、スタートアップ、海外事例、業界メディア、インフルエンサーのブログ。全部入っていた。
これを全部追うと、週次レポートが100ページを超えて、結局読まなくなる。情報が多いことは、情報がないことと同じだ。
監視対象は、次の3つのカテゴリに絞ってほしい。
直接競合 3〜5社
自分と同じ客層に、同じような商品を売っている会社だ。5社で十分だ。10社追う必要はない。
見るべきページも絞る。1社あたり、料金ページ、サービス一覧ページ、事例ページ、ブログ一覧ページの4つまで。トップページは情報密度が低いので外していい。
業界の定点 2〜3ヶ所
業界の動きを俯瞰できるメディアやレポートだ。日本国内なら、業界団体の発表ページや、大手メディアの特集ページがこれにあたる。
参考にしたい異業種 1〜2ヶ所
自分の業界ではないが、マーケティング手法やブランディングが参考になる会社だ。ここは趣味と実益を兼ねていい。
全部合わせて、10ヶ所前後に収めてほしい。多くても15ヶ所までだ。これより増えると、必ず破綻する。
変更検知をどう組むか
監視対象が決まったら、次は定期的に取得して比較する仕組みだ。ここで「プログラミングが必要そうで怖い」と感じた人もいるかもしれない。安心してほしい。非エンジニアでも動かせる方法がある。
方法は3つある。自分のスキルレベルに合わせて選んでほしい。
方法1 GitHub Actions を使う
GitHub(プログラマー向けのファイル共有サービス)には、Actionsという自動実行の仕組みが無料でついてくる。1日1回、決まった時間に指定したURLを取りに行って、前回の結果と比較するだけなら、数十行の設定で済む。
差分が出たら、自分のメールかSlackに通知する。これで完成だ。無料枠の範囲で、月3000分まで動かせる。個人事業主の使い方なら、まず使い切らない。
方法2 Google Apps Script を使う
Googleスプレッドシート上で動く自動化スクリプトだ。スプレッドシートにURL一覧を書いておいて、毎朝Jina Reader で取得して、前日のテキストと比較して、変更があればセルに印をつける。
これのいいところは、全部Googleアカウントの中で完結することだ。新しいサービスに登録する必要がない。
方法3 既存の変更検知サービスを使う
Visualping や Distill.io といった、ウェブページの変更を検知してくれる有料サービスがある。月1000円前後から使える。自分でコードを書きたくない人は、ここから始めていい。
ただし、これらのサービスは汎用的に作られているので、不要な変更(日付の表示やアクセスカウンターなど)まで拾ってしまうことがある。Jina Reader と組み合わせることで、本文だけを比較できるので、ノイズが減る。
具体的な手順 GitHub Actionsでの組み方
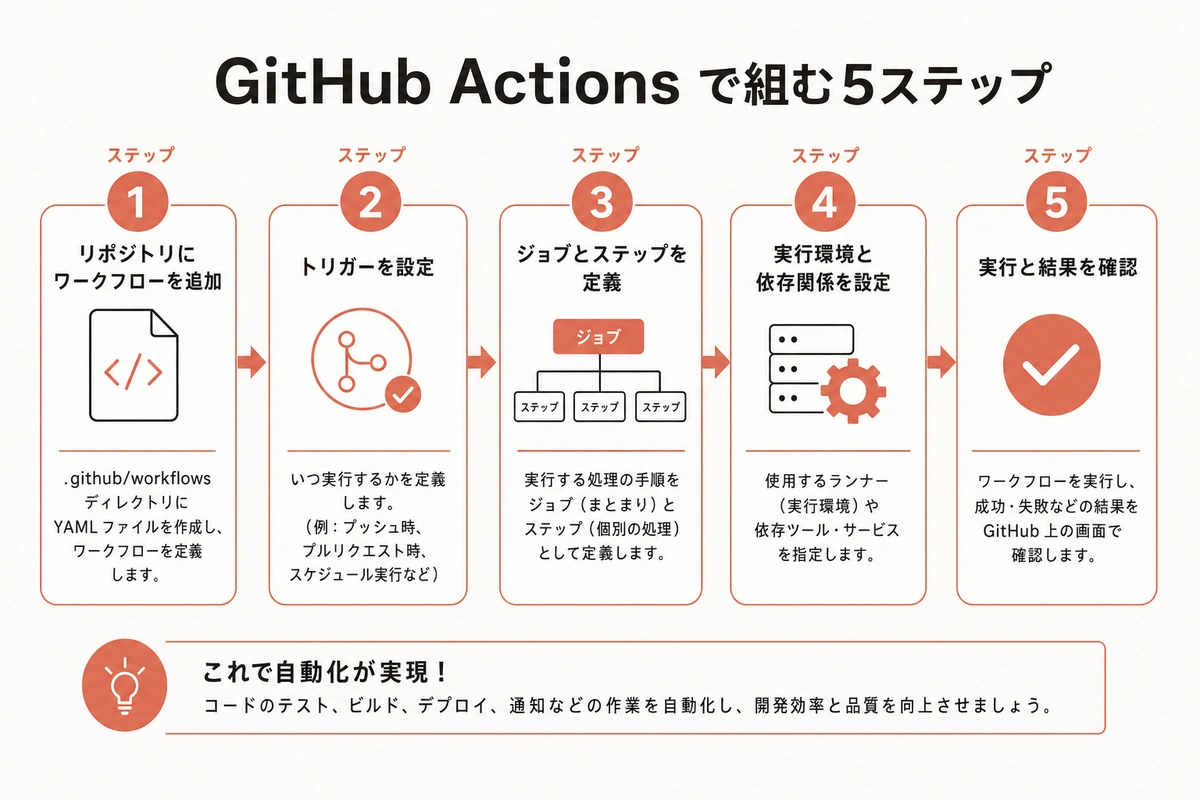
一番拡張性があるGitHub Actionsのやり方を、順を追って書く。コードが出てくるが、ほとんどはコピーで済む。
ステップ1 監視リストをファイルにする
watchlist.txt という名前のファイルを作って、1行に1URLずつ書く。
https://example-a.com/pricing
https://example-a.com/cases
https://example-b.com/service
https://example-c.com/blog
これだけだ。後から追加したり減らしたりするときは、このファイルを編集する。
ステップ2 取得スクリプトを書く
スクリプトといっても、やることは単純だ。リストを読み込んで、1つずつJina Reader に投げて、結果をファイルに保存する。
#!/bin/bash
mkdir -p snapshots
while IFS= read -r url; do
filename=$(echo "$url" | sed 's/[^a-zA-Z0-9]/_/g')
curl -s "https://r.jina.ai/$url" > "snapshots/$filename.txt"
done < watchlist.txt
このスクリプトを走らせると、snapshots というフォルダに、各ページのテキストが保存される。
ステップ3 差分を取る
前回の結果と今回の結果を比較する。diff というコマンドを使えば、変わった行だけを抽出できる。変わった行がある場合だけ、レポートに書き出す。
#!/bin/bash
report="report.md"
echo "# 今週の変更点" > $report
for file in snapshots/*.txt; do
name=$(basename "$file" .txt)
if [ -f "previous/$name.txt" ]; then
diff_result=$(diff "previous/$name.txt" "$file")
if [ -n "$diff_result" ]; then
echo "## $name" >> $report
echo '```' >> $report
echo "$diff_result" >> $report
echo '```' >> $report
fi
fi
cp "$file" "previous/$name.txt"
done
これで、変更があったページだけがreport.md に書き出される。
ステップ4 週次で実行する
GitHub Actionsの設定ファイル(.github/workflows/watch.yml)に、週次実行の指定を書く。毎週月曜の朝9時に走る設定は、こうだ。
on:
schedule:
- cron: '0 0 * * 1'
cron(定期実行の書式)は慣れないと読みにくいが、この1行だけ覚えれば十分だ。毎週月曜のUTC 0時、日本時間で月曜朝9時に動く。
ステップ5 レポートを受け取る
できあがったreport.md を、自分のメールに送るか、Slackのチャンネルに投げる。GitHub Actionsには、これを実現する既成の部品が揃っている。
月曜の朝、メールを開くと、先週1週間で競合サイトに起きた変更がまとまって届いている。これを読むのに、15分から30分あれば足りる。
AIに要約させるひと工夫
さらに便利にしたいなら、diff の結果をそのまま見るのではなく、Claude API(AIに文章を処理させる仕組み)に要約させるといい。
プロンプト例を書いておく。
以下は競合A社の料金ページの変更差分です。
ビジネス上の意味を3行で要約してください。
- 何が変わったか
- なぜ変えたと考えられるか
- 自社への示唆
差分:
(ここに diff の結果を貼る)
これを監視対象ごとに流すと、生の差分ではなく、意味を解釈したレポートが届く。料金が5000円値上がりしたこと、新プランが追加されたこと、FAQが刷新されたこと。そういう情報が、人間の言葉で要約される。
月に一度、このレポートを3時間かけて読み込む。気づきをメモする。自分の商品ページや提案書に反映する。これだけでいい。
週次レポートの読み方
レポートが届いたら、読み方にもコツがある。
最初は全部読もうとしないことだ。ざっと眺めて、目を引いた箇所だけを深掘りする。レポートの8割は、小さな文言修正や、ブログの新着通知で、大きな意味はない。残りの2割に、重要な変更が紛れている。
重要な変更とは、こういうものだ。料金の変更、プラン構成の変更、新サービスの追加、ターゲット顧客の変更を示唆する表現、採用ページの職種変更。特に採用ページは、その会社が次に何をやろうとしているかを雄弁に語る。
月に一度、これらをまとめて眺めて、自分の事業に対する示唆を書き出す。A4一枚のメモでいい。そのメモを、四半期に一度見返す。これで、競合の動きに対する感度は、毎日チェックしていた頃の何倍にもなる。
よくある失敗と落とし穴
この仕組みを試した人から聞く失敗談を、先に共有しておく。
監視対象を増やしすぎる
最初は10ヶ所でスタートして、途中で「あの会社も入れよう」「この業界メディアも」と足していくうちに、40ヶ所になっている。レポートが長すぎて読めなくなる。
対策は、1つ追加するときに1つ減らすルールだ。これを守れば、リストが膨張しない。
差分ノイズに疲れる
ウェブページには、日付表示、アクセスカウンター、ランダム表示のバナーなど、毎日変わる要素がある。これらが差分として検出されると、レポートがノイズだらけになる。
対策は、監視するページを本文密度の高いページに絞ることだ。トップページではなく料金ページ、新着記事一覧ではなく記事個別ページを指定する。それでもノイズが多いサイトは、諦めて監視対象から外していい。
仕組みを作ることが目的になる
一番多い失敗だ。自動化の仕組みを作るのが楽しくなって、2週間かけて完璧なダッシュボードを作り、肝心の競合分析を忘れる。
対策は、最初の1周は手動でもいい、と割り切ることだ。watchlist.txt にURLを10個書いて、手動でJina Reader を開いて、テキストをコピーして、先週分と比較する。これを1時間でやる。これができれば、自動化はその後で十分だ。
レポートを読まない
仕組みは動いている。毎週月曜にレポートが届く。でも、開かない。3ヶ月後、全部読んでいないことに気づく。
対策は、レポートを受け取る日を、カレンダーに予定として入れることだ。月曜の朝9時から30分、レポートを読む時間として確保する。さらに、月初の1日は、3時間のブロックを取って、月次の深掘り読みをする。予定に入っていないことは、絶対にやらない。自分は意志が強い、という思い込みを捨てる。
AI要約を過信する
Claude APIでの要約は便利だが、たまに間違える。値上げしていないのに値上げしたと書いたり、新プランを見落としたりする。
対策は、要約はあくまで目次として使い、気になったものだけ元のdiff を確認することだ。レポートには必ず元リンクと生の差分を含めておく。
明日からやる3つのこと
最後に、この記事を読み終わったあと、明日から実際にやってほしいことを3つだけ書く。
1 watchlist.txt を作る
メモ帳でもGoogleドキュメントでもいい。競合とみなすべき会社のURLを、10個書き出してほしい。10個で止める。これが一番大事だ。
書き出してみると、意外と10個埋まらないことに気づくはずだ。それでいい。5個でも7個でも、その数が自分にとってのリアルな競合の数だ。
2 Jina Reader を手動で使ってみる
リストの1つ目のURLに、https://r.jina.ai/ をつけて、ブラウザで開いてほしい。出てきたテキストを、任意のファイルに保存する。
これだけで、仕組みの半分は動いたことになる。来週の同じ日に、もう一度同じことをして、diff サイトで比較してみる。差分が可視化される感覚を、まず自分の目で確認してほしい。
3 月次の深掘り時間をカレンダーに入れる
来月、再来月、その次の月。3ヶ月分、月の第1月曜の午前中に3時間のブロックを入れる。予定名は「競合深掘り」でいい。
この時間を守れるかどうかが、仕組みが機能するかどうかを決める。自動化の仕組みは後からでも組める。でも、思考する時間を確保しない限り、情報は情報のままで、何の価値も生まない。
競合リサーチは、毎日やるものではない。月に一度、深く考えるものだ。そのための材料集めを機械に任せて、浮いた時間で自分にしかできない思考をしてほしい。月3時間で、十分間に合う。



