
個人開発でいちばん効く改善は、実は『同時に動かす数を増やすこと』です。
一人で開発していると、機能Aに手を付けている間、機能BもCも完全に止まります。ひとつずつ順番に仕上げるしかない——そう思い込んでいる方がほとんどではないでしょうか。
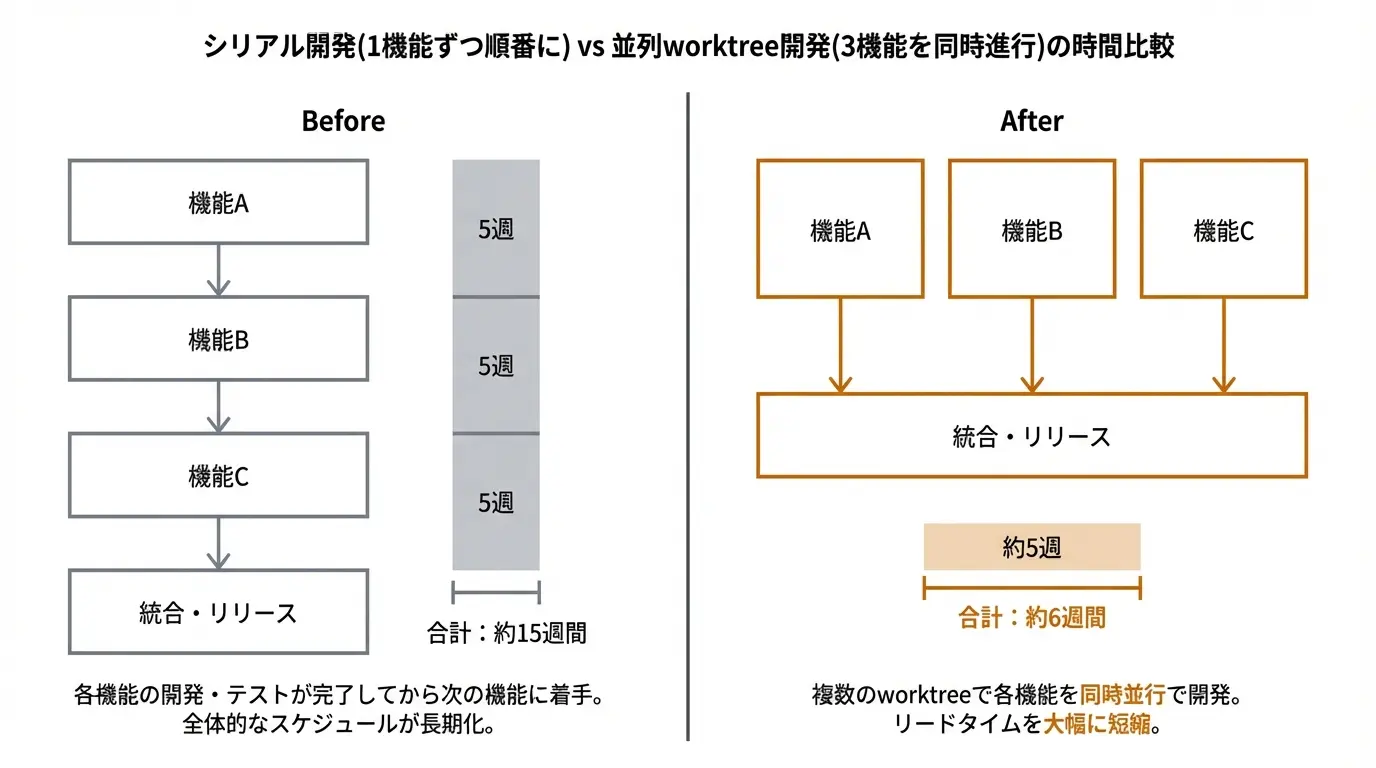
しかし、ある個人開発者はこの常識を覆しました。彼は新機能3つを3つの『作業フォルダ』に分け、それぞれで独立したClaude Codeのサブエージェント(=役割を持たせたAIの働き手)を同時に走らせています。1つのリポジトリなのに、3人の開発者が並行して働いているような状態です。結果、開発速度は体感2.5〜3倍になりました。
この仕組みの中心にあるのが git worktree(=同じリポジトリを複数の作業フォルダに分裂させる機能)です。本記事では、この運用を非エンジニアの方でも真似できるよう、比喩を交えて丁寧に解説します。
そもそもgit worktreeとは何か
git worktreeは、ひとつのリポジトリ(=ソースコード一式の保管庫)を、複数の作業フォルダに『分身』させる仕組みです。
比喩で言うと、ひとつの工場に3本のベルトコンベアを並べる ようなものです。同じ部品倉庫(=リポジトリ本体)を共有しながら、各ラインでは違う製品を同時に組み立てられる。これがworktreeの本質です。
従来のやり方では、ブランチ(=作業の枝分かれ)を切り替えるたびに、いま手元にある変更を一度片付ける必要がありました。worktreeを使えば、そもそもフォルダ自体が分かれているので、片付ける必要がありません。
コマンドはシンプルです。
git worktree add ../feature-a feature/a
git worktree add ../feature-b feature/b
git worktree add ../feature-c feature/c
読めなくても大丈夫。要点はこうです。『feature-a / feature-b / feature-c という3つのフォルダを作り、それぞれで別のブランチを開いた』 これだけです。
なぜworktreeとAIエージェントは相性がいいのか
Claude Codeのようなコーディングエージェントは、『いま自分がいるフォルダ』の中身を読み、考え、書き換えます。逆に言えば、別フォルダで何が起きているかは一切知りません。
これが並列実行の決定的な利点になります。
同じフォルダで2つのエージェントを動かすと、お互いの変更を踏みつぶし合ってしまいます。ところがworktreeで物理的にフォルダが分かれていれば、エージェントAは自分の作業に集中し、エージェントBの存在すら認識しません。競合は発生しようがない のです。
比喩で言えば、新入社員3人に別々の会議室を与えて、それぞれ別のタスクをやらせている 状態です。全員が同じ会議室にいたら互いの資料を取り合って混乱しますが、部屋が分かれていれば平和に作業が進みます。
3倍速を支える6つのレイヤー
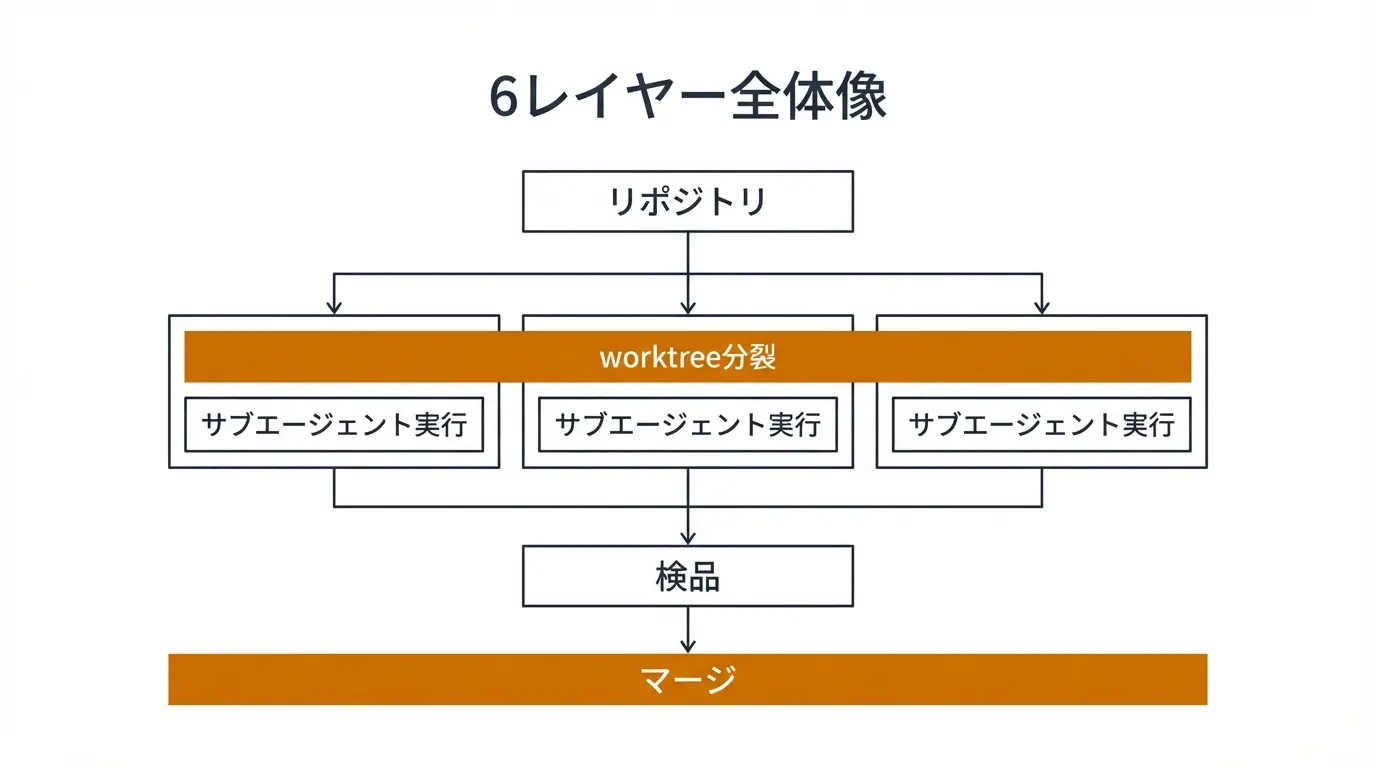
この運用は、6つのレイヤー(=階層)で成り立っています。
レイヤー1: worktreeの作成
前述のコマンドで、機能ごとに作業フォルダを用意します。命名規則は ../プロジェクト名-機能名 のような形が推奨されています。
レイヤー2: 責任範囲の切り分け
ここが最重要です。各worktreeで触るファイルを事前に決めておく こと。例えば:
- worktree A:
app/articles/配下のみ触る - worktree B:
lib/ai/配下のみ触る - worktree C:
components/配下のみ触る
これを守る限り、最後のマージ(=各フォルダの成果を本体に統合する作業)でコンフリクト(=衝突)はほぼ起きません。比喩で言えば、新入社員の就業規則 を渡しておくイメージです。
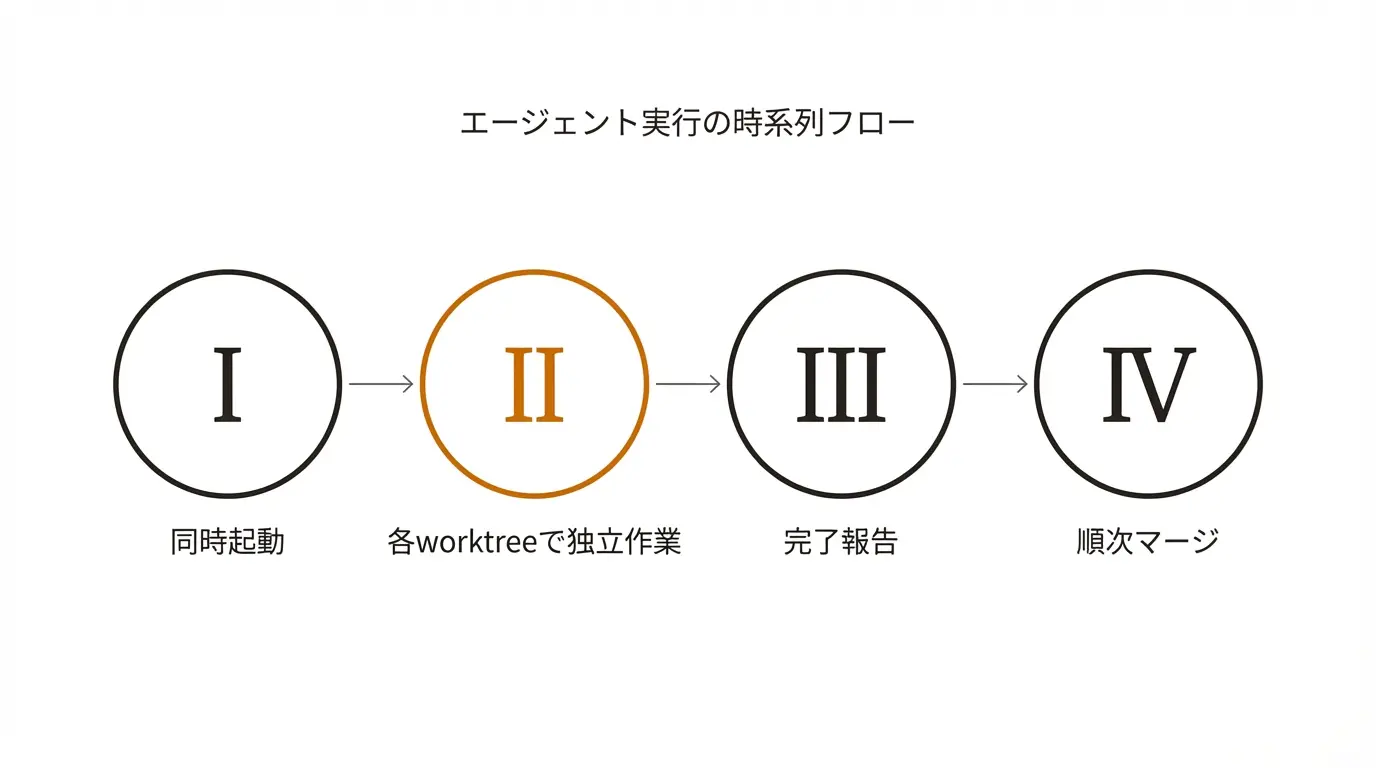
レイヤー3: サブエージェントの起動
各worktreeで claude コマンドを立ち上げ、それぞれに異なるタスクを与えます。ターミナルを3つ開き、各ウィンドウで別々の指示を出すだけ。
レイヤー4: 独立実行
エージェントは自分の会議室(=worktree)の中だけを見て、黙々と作業します。ユーザーは時々進捗を確認するだけでOKです。
レイヤー5: 検品ゲート
各worktreeで作業が終わったら、テスト・型チェック・リント(=コードの文法チェック)を走らせます。これが 検品ゲート です。ここを通ったものだけを次のレイヤーに送ります。
レイヤー6: マージ戦略
完成したブランチは、ひとつずつpull request(=変更をまとめて提出する仕組み)として提出し、順番にmainブランチへ統合します。一気にまとめてマージしない のがコツです。ひとつ通してから次、という順序を守れば、万が一問題が出ても切り戻しが楽になります。
コスト効率の話
見落とされがちですが、この運用は コスト効率 も優秀です。
Claude Codeを使う際、1回の実装ラウンドで発生する思考コストは、機能の数に単純比例しません。3つ並列で回せば、1回の『考える時間』で3機能分の成果物 が返ってきます。個人開発者にとって、この複利効果は想像以上に大きい。
時間もお金も、3倍速で回収できるイメージです。
よくある落とし穴
- 同じファイルを複数worktreeで触ってしまう: 責任範囲の切り分けをサボると発生します。事前にメモに書き出しておくこと。
- マージを溜め込む: 完成したら即マージ。溜めると全部がコンフリクトの温床になります。
- worktreeの掃除を忘れる: 使い終わったら
git worktree removeで片付けます。放置するとディスクを圧迫します。
エンジニアじゃない方へのメッセージ
ここまで読んで『やっぱり自分には無理そう』と感じた方へ。
大丈夫です。この仕組みの9割は、最初にセットアップするだけで、あとは同じコマンドを繰り返すだけ です。運用スクリプトさえ手元にあれば、『3つの機能を同時に作って』とAIに頼むのと同じ感覚で使えます。
個人事業をこれから立ち上げたい方にとって、『ひとりで複数案件を同時に進められる』というのは、それ自体が大きな武器になります。技術的な理解は後からで構いません。まずは手を動かして、動く状態を作ってしまうのが近道です。
🎁 特典: 設定ファイル一式ダウンロード
本記事で紹介した運用を、そのままコピペで始められるスクリプト一式をzipにまとめました。
zipの中身:
worktree-create.sh— 機能名を渡すだけでworktreeを一発作成worktree-cleanup.sh— 完了したworktreeを安全に一括削除parallel-run.sh— 複数worktreeで並列にサブエージェントを起動する呼び出し例merge-strategy.md— マージ順序・コンフリクト回避のチェックリストresponsibility-template.md— 責任範囲を事前に書き出すためのテンプレート
解凍して、あなたのプロジェクトのパスに書き換えるだけ で、今日から3倍速開発を始められます。
📚 参考リファレンス
実際に手を動かす際は、以下の一次情報を合わせて参照することが推奨されています。



